モバイル空間統計のリアルタイム化 × AI 技術 = 未来予測?
~ 「いま」がわかれば「未来」がわかる ~
2018年03月30日
「モバイル空間統計」は、2013年10月の分布統計(国内居住者)提供開始以降、訪日外国人や動態統計、さらにはより詳細な属性が分析できる詳細分析オプションなど、様々な機能を追加してきた。今回は、モバイル空間統計の進化「リアルタイム化」と、リアルタイム化で広がる可能性について、ドコモの主任研究員 寺田氏に話を聞いた。
このコラムは、「すこし先のモバイル空間統計」について先進的な話題を提供する、という位置付けのものである。今回はその第一回ということで、ちょっと (かなり?) 尖った話として、モバイル空間統計をリアルタイム化すると未来に起こることが予測できる、すなわち「未来予測」ができるということについて書いてみたい。
NTTドコモの先進技術研究所では、モバイル空間統計をリアルタイム化した「リアルタイム人口統計」とその応用に関する研究開発を進めている。リアルタイム人口統計は、モバイル空間統計と同様に、日本全国の人口を500mメッシュ (政令指定都市中心部など一部地域は 250m メッシュ) 単位で、性年代別 (5才刻み)、居住市区町村別に推定する。モバイル空間統計と最も違うのは「リアルタイム化」の部分であり、これらの人口の10分ごとの変動を、約20分で推定することができる。つまり、12:00 の人口は 12:20 に、12:10 の人口は 12:30 には知ることができることになる。

モバイル空間統計のリアルタイム化により何が便利になるだろうか。ひとつには、従来のモバイル空間統計の活用法の延長として、PDCA サイクルの迅速化が挙げられる。たとえば広告宣伝による集客効果をモバイル空間統計で検証したい、というときに、いままでは1ヶ月~1。5ヶ月後 (2営業日後に仮の推計結果を得られる「速報値」と呼ばれるメニューもある) になって結果を得られていたものが、その日のうちに検証の材料を得られるようになる。
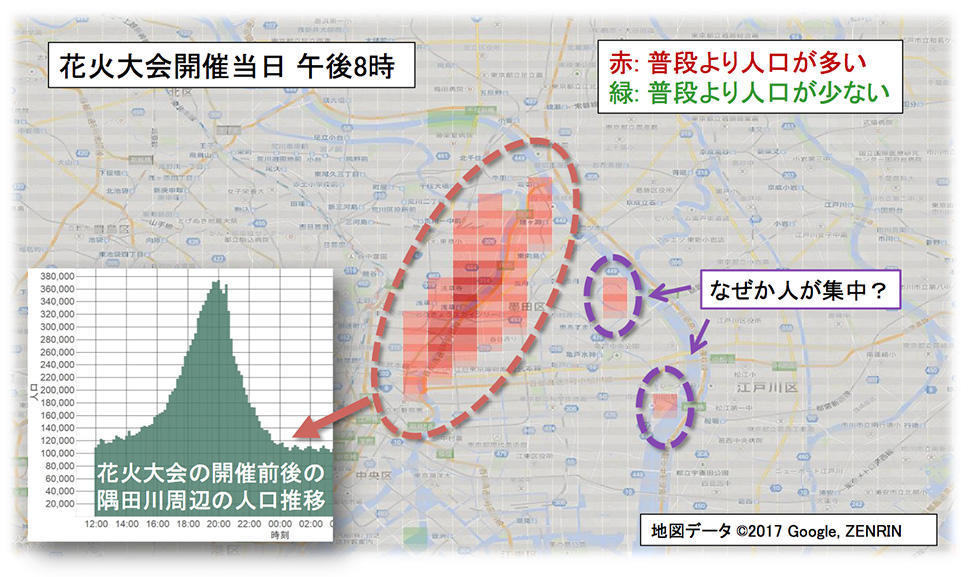
また、たとえばイベントなどでの来訪者の状況によって警備体制を柔軟に変更・充実させる、という応用も考えられるだろう。図1はある年の隅田川花火大会の来訪者数を500mメッシュ単位で推計したものである (赤が濃いほど来ている人が多いことを意味する)。隅田川に沿って見物客が多く集まっていることがわかるが、川から東のほうに少し離れたところに、2ヶ所ほど人が集まっているところがある。何でこんなところに人が...?と調べてみたら、地元の方らしき人のblog に、花火が (少し遠いながら) ゆったりと良く見える「穴場スポット」だよ、との情報があった。このような「なぜかわからないけど妙に人が多く集まっている」場所がわかることを応用すると、たとえば2020年の東京オリンピックの頃には、そういうところにまずはちょっとドローンを飛ばして様子を見てみる、などの新しい警備の形が見られるかもしれない (ドローンの落下対策など、実現には他の課題もあると思われるが)。
このように、モバイル空間統計を「より早く」提供できるという観点で広がる使い途もいろいろと考えられる。しかし、ここではモバイル空間統計の延長から少し離れ、広域的な人口変動のダイナミクスが「リアルタイムに」把握できることの意味を考えてみたい。
人口変動のダイナミクス、ひらたく言えばある地域で人が増えたり減ったりしていることがリアルタイムで継続的にわかると、何がわかるのだろうか。少し専門的な言葉を使うと、人口との間に「(相互)相関」と呼ばれる関係を持つ事象のことがわかる。特に人口が「先行指標」となる事象に対しては、人口からその事象に関する予測をすることができる。すなわち、「いま」の人口から「未来」の事象を予測できることになる。
相関とは、簡単に言えば、あるものが増えたり減ったりすると、別のあるものが増えたり減ったりする、という関係である。たとえば、夏場に気温が高くなるとアイスクリームの売上が増える。逆に涼しいと売上が減る。すなわち「気温」と「アイスクリームの売上」は相関を持つ。過去の気温変化とアイスクリームの売上実績に基づいて定量的に計算すれば、どちらかの数字がわかるともう片方の数字もだいたい推定できるようになる。また、雨が降ると、しばらくしてから川の水位が上がる。雨がやめば、しばらくして水位は下がる。この「降水量」と「川の水位」の関係のように、時間差つきで相関を持つ場合もある。先に変化するほうを「先行指標」と呼び、後に変化するほうを「遅行指標」と呼ぶ。降水量のほうが川の水位よりも先に変化することから、降水量は川の水位に対する先行指標となる。この場合、過去の降水量の変化と (時間差を考慮した) 川の水位の変動に基づいて計算すれば、いままでの降水量からこれからの川の水位の変動を予測できる。つまり、先行指標は遅行指標の「未来」を予測する能力を持つと言える。
すなわち、降水量と川の水位の関係のように、人口を先行指標とするような社会事象や経済事象があれば、「いま」の人口を知ることによりそれらの「未来」を予測できる可能性がある。さて、人口はどんな事象の先行指標になるのだろうか。

さまざまな社会活動や経済活動は、すべからく人間の営みとして行なわれるものである。ということを鑑みると、人口が先行指標となる社会事象や経済事象の候補はいろいろとある。身近な例の一つとして交通渋滞が挙げられる。たとえば、人気がある行楽エリアからの帰り道は頻繁に渋滞する。なぜ渋滞するかというと、(あたり前だが) 人がたくさん集まるからである。イベントなどにより普段よりたくさん人が集まると渋滞は激しくなり、逆に悪天候などで人出が少ないと渋滞は小規模になったり、そもそも発生しなかったりする。これは、行楽エリアの人出は、そこへのアクセス道路の帰りの渋滞の先行指標となりうることを意味する。すなわち、「いま」の人口によって「未来」の渋滞の発生やその規模などを予見できる可能性を示唆する。
2017年12月からNEXCO東日本とNTTドコモが共同で実施している「AI渋滞予知」の実証実験は、この「人口が渋滞の先行指標となる」という性質に基づいて、夕方から夜にかけて頻発する東京湾アクアラインの渋滞を、昼の房総半島の人口分布から予測するものである。その予測結果は、NEXCO東日本が運営する交通情報Webサイトである「ドラぷら」を通じて一般に公開されている。なお、この実証実験では、渋滞にはまって時間をムダに過ごすよりは、木更津などでおトクにグルメやショッピングを満喫しましょう、という主旨のクーポン(「ヨル得クーポン」と呼ばれる)を渋滞の予測結果と併せて提供し、帰宅時間帯の分散 (による渋滞の緩和) と地域経済の活性化を促している。
AI渋滞予知は、(その名の通り)人口から渋滞を予測するにあたってAIの一種である「機械学習」と呼ばれる技術を用いている。房総半島に人口が多いと渋滞が起こりやすくなることはなんとなく想像できるとしても、他に何も情報がなければ、どこにどのくらいの人がいると、どのくらいの規模の渋滞が、どの時間帯に発生するかという具体的なことはわからない。そこで、過去の人口分布と渋滞実績をたくさんAIに「学習」させて、昼の人口分布から夕方の渋滞を予測するための数式を作る。この学習により作られた数式を「渋滞予知モデル」という。この渋滞予知モデルは、少し乱暴な言い方をすると「同じような人口分布を持つ日は、同じように渋滞する」という原理に基づいて渋滞を予測する。つまり、ある人口分布が入力されたとき、過去にその人口分布に「似た」人口分布を持つ日があれば、その「似た」日における渋滞実績を参考にして渋滞を予測して出力する (図2)。
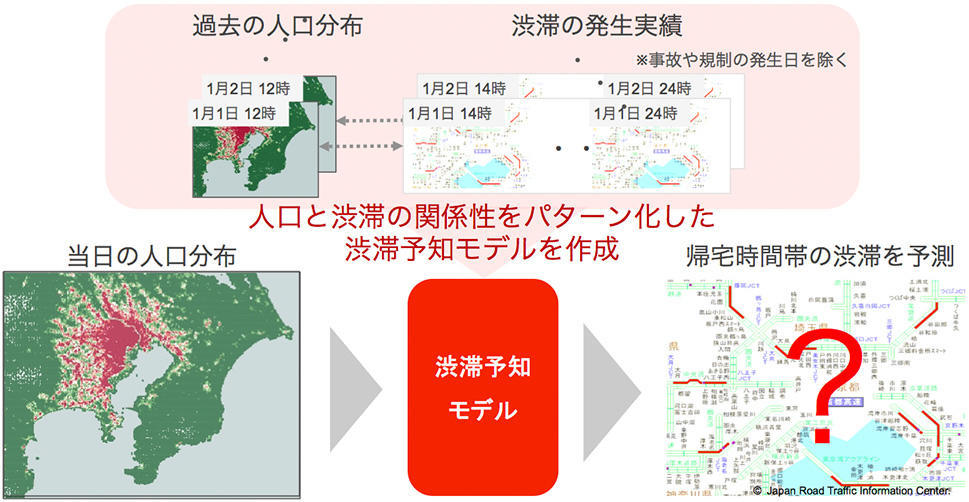
ここで、何をもって人口分布が「似ている」と判断するかが予測精度を上げるためのカギとなる。たとえば、房総半島で人出がいくら多くても、それが千葉県民の方々ばかりであれば東京湾アクアラインの渋滞に影響することはほとんどないだろう。やはり東京や神奈川から来ている人の多さが効いてくるし、同じ東京でも東部と西部とで影響の大きさは異なる (しかも、房総半島のどこにいるかによって影響の大きさに違いが出る)。ここで、モバイル空間統計が居住市区町村別に人口を推計できることが強みとなる。つまり、「どこから来た人か」などの属性も含め、渋滞への影響の大きさに応じて人口分布のデータに重みをつけたり変形したりすることによって、人口から渋滞を精度良く予測することができるようになる。
理論的には上記の通りAI技術を使って人口から渋滞を予測できるものとして、実際問題としてどのくらいの予測能力を持つものだろうか。実証実験に先立って実施した精度評価の結果を表1に示す。NEXCO東日本が従来から提供している「渋滞予報カレンダー」と比較して、たとえば10km 以上の渋滞の見逃し率は 6% → 1% に、同じく空振り率は 18% → 0% に、それぞれ大幅な改善を見ることができた (2015年1月~2017年4月までの2年4ヶ月を対象とした交差検証 (leave-one-out cross validation、 LOOCV) による評価結果。ただし事故や交通規制の発生日を除く)。ここで、渋滞の見逃し率とは、渋滞が発生した日のうち「渋滞しない」と予測してしまった日の割合 (false negative rate、 FNR) を指し、空振り率とは、「渋滞する」と予測したにもかかわらず実際には渋滞しなかった日の割合 (false discovery rate, FDR) を指す。
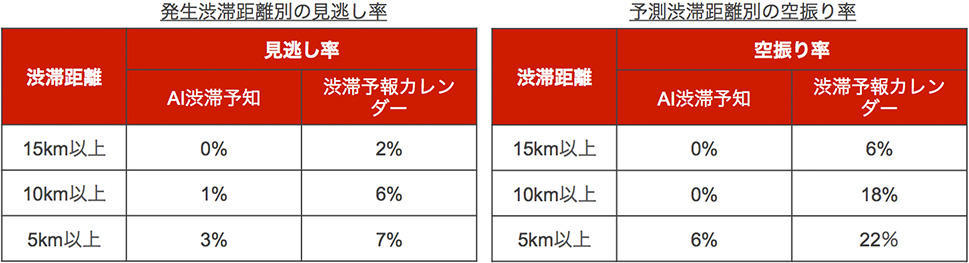
なお、この予測にあたっては、曜日や天候、イベント開催情報など、人口以外の情報は一切使っていない (人口と渋滞の関係性を学習させるために過去の渋滞実績や事故・規制情報は利用している)。すなわち、人口の渋滞に対する先行指標としての予測能力を、そのまま反映した数字であるといえる。予測に人口以外の情報を使っていない、と言うと少し驚かれることもあるが、そもそも人口分布というものは曜日や天候、イベントなど様々な要因による人出の変動が反映されたデータであるため、予測にあたってそれらの情報をあらためて参照する必要がない (すでに「折り込みずみ」とみなすことができる)。予測にあたって他のデータへの依存を減らすことができるという点は、実際のシステム構築を考えると面倒が減って便利なところでもある。

また、人口がタクシー需要の先行指標となることに着目すると、タクシー需要の予測や、それに基づくタクシー需給の最適化を図ることができる。これは、「AIタクシー」として実証実験が行われ、2018年2月から商用サービス提供がなされている。AIタクシーの詳細は、ドコモのホームページに詳しく紹介されているので、興味がある方はぜひ参照していただきたい。
先に述べたように、さまざまな社会活動や経済活動は、すべからく人間の営みとして行なわれるものである。今回は「いま」の人口分布から「未来」の渋滞を予測する、という話について紹介したが、その観点から考えると、その他にもいろいろな「未来」の予測に使える可能性がある。今後のAI渋滞予知の進化も含め、機会があればまたご紹介したい。

寺田 雅之
Masayuki Terada
(株) NTTドコモ 先進技術研究所 主任研究員
1995年 神戸大学大学院工学研究科 修士課程修了。同年 日本電信電話(株)入社。同社情報通信研究所。情報流通プラットフォーム研究所を経て、2003年 (株)NTTドコモへ転籍。2008年 電気通信大学大学院電気通信研究科 博士後期課程修了、博士(工学)。2009年より現職。プライバシー保護技術の研究とビッグデータへの応用、モバイル空間統計の推計アルゴリズムの開発、リアルタイム計算手法の確立、渋滞予測への適用手法の研究などに従事。2015年度 情報処理学会論文賞、2015年度 同学会山下記念研究賞受賞。2017年度より情報処理学会コンピュータセキュリティ研究会主査。情報処理学会、電子情報通信学会会員。